

Introduction:
How can machines learn to navigate unfamiliar territories, play complex games with strategic prowess, or even outperform human decision-making? The answer lies in the captivating realm of reinforcement learning. Within this domain, one algorithm stands out for its ability to teach intelligent agents to make optimal choices without prior knowledge of the environment, and that is Q-learning.
In this blog post, we embark on an exhilarating exploration of the inner workings of Q-learning, uncovering its fundamental principles, practical applications, and the transformative impact it has had on the field of machine learning. Get ready to dive into the extraordinary world of Q-learning and witness the magic of training intelligent agents.
Understanding Reinforcement Learning:
Before we dive into the intricacies of Q-learning, let us grasp the fundamental concepts that underpin reinforcement learning. At its core, reinforcement learning involves an agent actively interacting with an environment, receiving feedback in the form of rewards or penalties based on its actions, similar to the dog training process illustrated below. The agent's primary objective is to learn the most effective course of action to maximize cumulative rewards over time. This unique paradigm distinguishes reinforcement learning from other branches of machine learning, making it particularly suited for scenarios where the agent learns through trial and error.
 |
| Training Dog Process |
The Q-Learning Algorithm:
Within the realm of reinforcement learning, Q-learning stands out as a straightforward and powerful algorithm that adopts a value-based approach. It is considered "model-free," meaning that it doesn't require prior knowledge or a detailed understanding of the environment's rules. In other words, Q-learning learns directly from trial and error, without needing to know how the environment transitions from one state to another.
The algorithm estimates the value of being in a particular state and taking a specific action, known as the Q-value. These Q-values are stored and organized in a table or function, allowing the agent to make informed decisions based on the expected rewards associated with different state-action pairs.
By continually updating these Q-values, Q-learning enables the agent to gradually improve its decision-making abilities and learn the most effective strategies. This approach also allows the agent to explore various actions while still leveraging its learned knowledge, striking a balance between exploration and exploitation for optimal learning.
 |
| Q-learning training loop |
Q-Table and Q-Function:
A crucial element of Q-learning is the utilization of a Q-table, which serves as a lookup table to store the Q-values associated with each state-action pair. Alternatively, a Q-function can be employed, wherein the state and action are used as inputs to derive the corresponding Q-value. Throughout the learning process, the agent updates the Q-values based on the rewards obtained and the estimated future rewards, allowing it to gradually refine its decision-making capabilities.
 |
| Q-table example |
Exploration and Exploitation:
Finding the delicate balance between exploration and exploitation is pivotal in reinforcement learning. Exploration involves the agent actively seeking new actions to gather information about the environment, whereas exploitation refers to the agent leveraging the knowledge it has acquired to make optimal decisions. Q-learning employs an ε-greedy policy, wherein the agent explores with a certain probability (ε) and exploits the acquired knowledge otherwise. This mechanism enables the agent to learn from both known and unknown scenarios, ensuring a comprehensive learning experience.

The Q-Learning Update Rule:
The core mechanism behind Q-learning lies in its update rule, often referred to as the Bellman equation. The update rule combines the immediate reward obtained after taking an action with the estimated future rewards, ultimately guiding the agent towards an optimal policy. Through iterative application of the update rule, the agent continually refines its Q-values, enhancing its ability to make informed decisions based on the expected rewards associated with different state-action pairs.

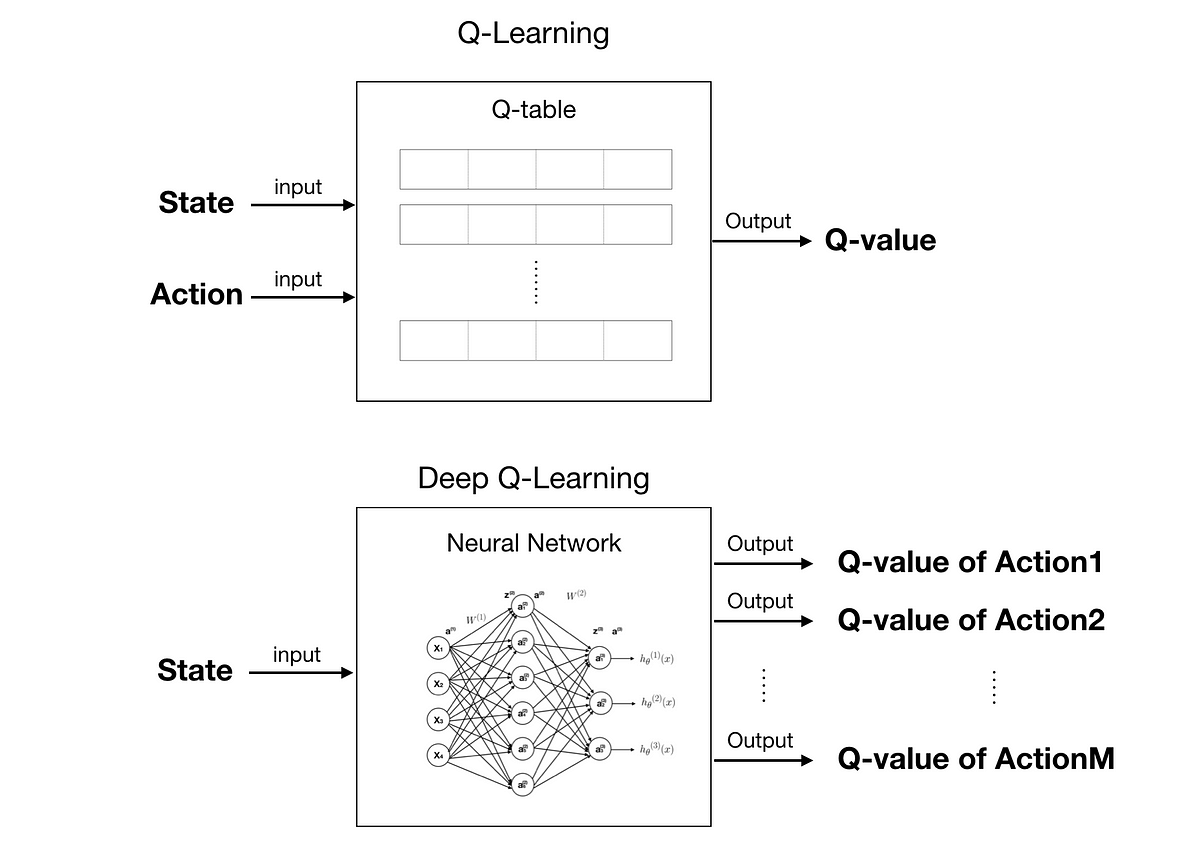
Deep Q-Learning:
While the basic Q-learning algorithm is effective for small-scale problems, it encounters challenges when applied to complex environments with high-dimensional state spaces. Deep Q-learning, a prominent extension, merges the power of Q-learning with deep neural networks, resulting in the creation of the Deep Q-Network (DQN). DQN utilizes neural networks to approximate the Q-values, enabling it to handle complex environments and overcome the limitations of traditional Q-learning.
Applications of Q-Learning:
The versatility of Q-learning is showcased through its diverse range of applications across various domains. For instance, Q-learning has been successfully employed in training autonomous robots to navigate through obstacle-filled environments, enabling them to adapt and learn in real-time. Furthermore, Q-learning has played a pivotal role in training game-playing agents, allowing them to conquer complex video games by learning optimal strategies.
Additionally, Q-learning has emerged as a game-changer in training game-playing agents, enabling them to conquer even the most challenging video games by acquiring optimal strategies. To witness the magic of Q-learning in action, I invite you to check out the video I have created, showcasing how Q-learning agents master a highly challenging puzzle game. Prepare to be amazed by the ingenuity and problem-solving capabilities of these intelligent agents!
Challenges and Extensions:
While Q-learning is a powerful algorithm, it does face certain challenges. These include the exploration-exploitation trade-off, convergence issues, and the curse of dimensionality in high-dimensional state spaces. To address these challenges and enhance performance, researchers have developed extensions and variations of Q-learning, such as Double Q-learning, Dueling Q-networks, and Prioritized Experience Replay. These advancements push the boundaries of Q-learning, paving the way for more robust and efficient reinforcement learning algorithms.
Conclusion:
Q-learning stands as a fundamental algorithm in reinforcement learning, offering a solid foundation for understanding more advanced techniques. By grasping the key concepts and mechanisms underlying Q-learning, you are equipped to explore its applications further and potentially contribute to the advancement of reinforcement learning research. With its ability to learn optimal policies through a combination of exploration and exploitation, Q-learning continues to be a significant force in tackling complex real-world problems.


